
数据结构(1)
在计算机科学中, 数据结构是计算机中存储, 组织数据的方式.为编程语言提供数据类型; 一个好的数据结构应该尽可能的使用较少的空间和时间资源, 支持各种程序的运行. 忘记在哪里看到的了, 一个程序就是数据结构+算法; 常见的数据结构如下:
- 链表
- 数组
- 堆
- 栈
- 队列
- 哈希表
- 树
- 图
- …
链表
在物理内存上不一定是一段连续的存储空间, 增删的效率高于数组,因为他的特点是将数据与指标进行配对并指导计算机根据指标在内存中进行上/下一条数据的数据操作;增删的效率要比数组高, 因为不需要修改内存结构. 但是在查询上与数组一样, 都是线性查找;
单向链表
单向链表是链表中最简单的一种, 一个元素包含两个域,一个信息域和指针域;, 一个元素被分成两个部分, 信息域保存或者显示有关元素的信息, 另外一个部分存储链表中的下一个元素,形成链接, 最后一个元素的节点指针指向空.单向链表只能通过next指针指向下一个节点; 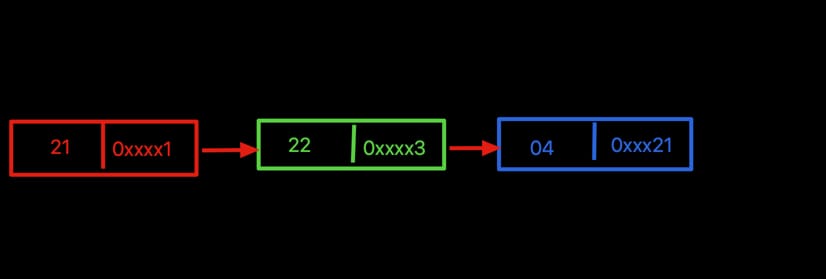
双向链表
双向链表比单向链表复杂一些, 比单向链表多了一个prev指针指向上一个节点, 也就是说第二个元素可以知道我上一个节点和下一个节点在 位置信息; 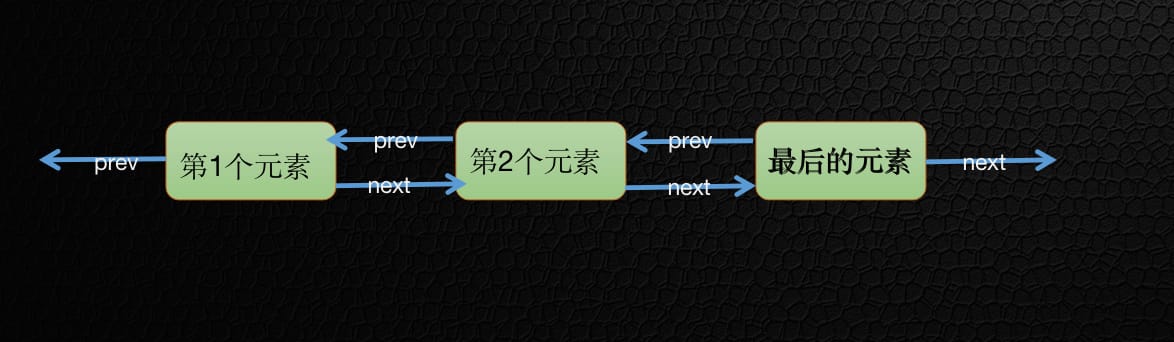
循环链表
循环链表中的首节点元素和末尾节点元素连接在一起. 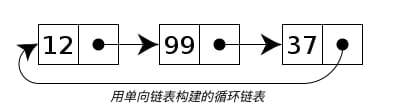
常见算法:
- 输入一个单向链表, 输出反转链表
1 | //单链表的转置,循环方法 |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.